
白玉堂前一树梅,为谁零落为谁开。唯有春风最相惜,一年一度一归来。 宋.王安石《梅花》
引子
仿佛一瞬间,2019 年的一月份就快过去了,然而迎接元旦的时刻似乎还历历在目。时间总是这么安静的流走,以它自己的节奏,不疾不徐。猛的发现,21 世纪也过去了将近 1/5 的时间了。
每一年,都会诞生各种各样的技术。有的经过实践的检验和逐步的完善,慢慢成为业界的标准或是最佳实践;有的则慢慢淡化直至完成使命,或者演化为其他技术。
在技术发展的上升阶段,总会有一些热点的技术,在一段时间被反复提起。它们诞生的初衷往往是一个很具象的痛点,然后在解决、完善之后,外延不断扩大,并最终成长为一个成熟的技术或者技术栈。
今天要说的 GraphQL 可能就是这样的技术。

为什么会有 GraphQL
随着前后端分离的开发模式不断的深入人心,越来越多的项目采用这种方式开发和部署。前端程序或是 App,多采用数据驱动的方式完成。数据可以采用数据接口的方式从服务端请求获得。主流的方式一般采用 REST API。
在 REST 风格的 API 中,接口数据被认为是一种“资源”,服务端提供 RESTful API,客户端通过 GET/POST/DELETE/PUT 等动作,通过 URI 对“资源”进行操作。
比如:GET /books/1 即是通过 GET 请求,访问 URI /books/1,也即服务端提供的/books/:id的 RESTful API,“获取”资源,得到如下返回:
{
"bookId": 1,
"title": "Black Hole Blues",
"author": {
"firstName": "Janna",
"lastName": "Levin"
},
"page": 260,
"press": "..."
}
这样的情景适应于现在的主流开发场景。不过也由一些痛点,下面列出几种:
- 后一个请求依赖前一个请求。在依赖比较多情况下,一般会造成多次请求。对于每次请求也都需要做失败情况的处理。
举个例子,我们需要查询某本书作者的详细信息。
现有接口:GET /books/:bookId返回形如下列格式:
{
"bookId": 1,
"title": "Black Hole Blues",
"authors": [
"authorId": 100
],
"page": 260,
"press": "..."
}
另有一个接口,可以获得作者信息:GET /authors/:userID返回形如下列格式:
{
"userId": 100,
"name":{
"firstName": "Janna",
"lastName": "Levin"
},
"age": ***,
"gender": "***",
"photos":[2, 3, 5, 7, 11, 13, 17, 19, 23]
如果只有这两个个最简单的接口,咱们的需求还是可以完成的:首先,先通过GET /books/1取得作者 ID,然后再通过GET /authors/100就取到了作者的信息。
这里,会有两次相继的请求。后面的请求严格依赖前面的请求。这样可能会造成以下几个问题:
(1)在业务上,对于多个作者的情况,可能需要请求的次数更多(可以提供多 ID 查询接口变相解决)
(2)请求时间长。即便启用了Keep-Alive也仅仅减少了重复建立链接的时间。
(3)如果第一次请求失败,需要对错误进行处理或重试。一方面会增大复杂度,另一方面极端的网络条件下,频繁的重试,对于服务端的压力是几何级的增长。
这样的情况,有的团队可能的做法是另外提供一个面对业务的整合接口,如: GET books/1/author/,可以间接地解决问题。
这样做的问题在于,一个前端界面上的问题,直接透给了服务端。业务的变化,会造成这种接口的爆炸增长抑或成批的废弃,给维护造成负担。
- 依然是上面的例子。现在对于多端的开发,需要的数据不同。如:手机上仅需获取作者,而 PC 上需要通过
photo字段所示的照片集取得第一张照片显示......。为了达到这样的效果,一般的团队可能会为每种端开发一种特定 API,或者是统一把最冗余的数据接口提供出去。这样显然都不是最理想的。



这些痛点至少代表大家在开发中经常遇到的情况。GraphQL 也许可以成为解决这些问题的一个不错的选择。
什么是 GraphQL
那么,什么是 GraphQL 呢?

GraphQL 是一套关于数据查询和操作的语法标准,它极为适合用于 API 交互。它由 Facebook 在 2012 年开发并在内部使用。2015 年对外发布。2018 年 11 月 7 日,GraphQL 由 Facebook 转交由新成立的 GraphQL 基金会管理。
简单的说来,GraphQL 提供了一种机制,允许客户端定义返回的数据结构。当数据返回时候,精确的根据定义返回所需的数据结构。这种机制避免了大量冗余数据的返回,也使得合并多次请求成为可能。
这里是 GraphQL 官方网站。国内还有一份中文的镜像网站。
GraphQL 确切讲是一种语言标准,是与实现语言无关的。实际上,Facebook 和开源届,已经有了针对 GraphQL 的各种语言的实现。
感受 GraphQL
为了对 GraphQL 有一个感性的认识,读者可以参考官方示例进行操作,完成一个 GraphQL 查询。
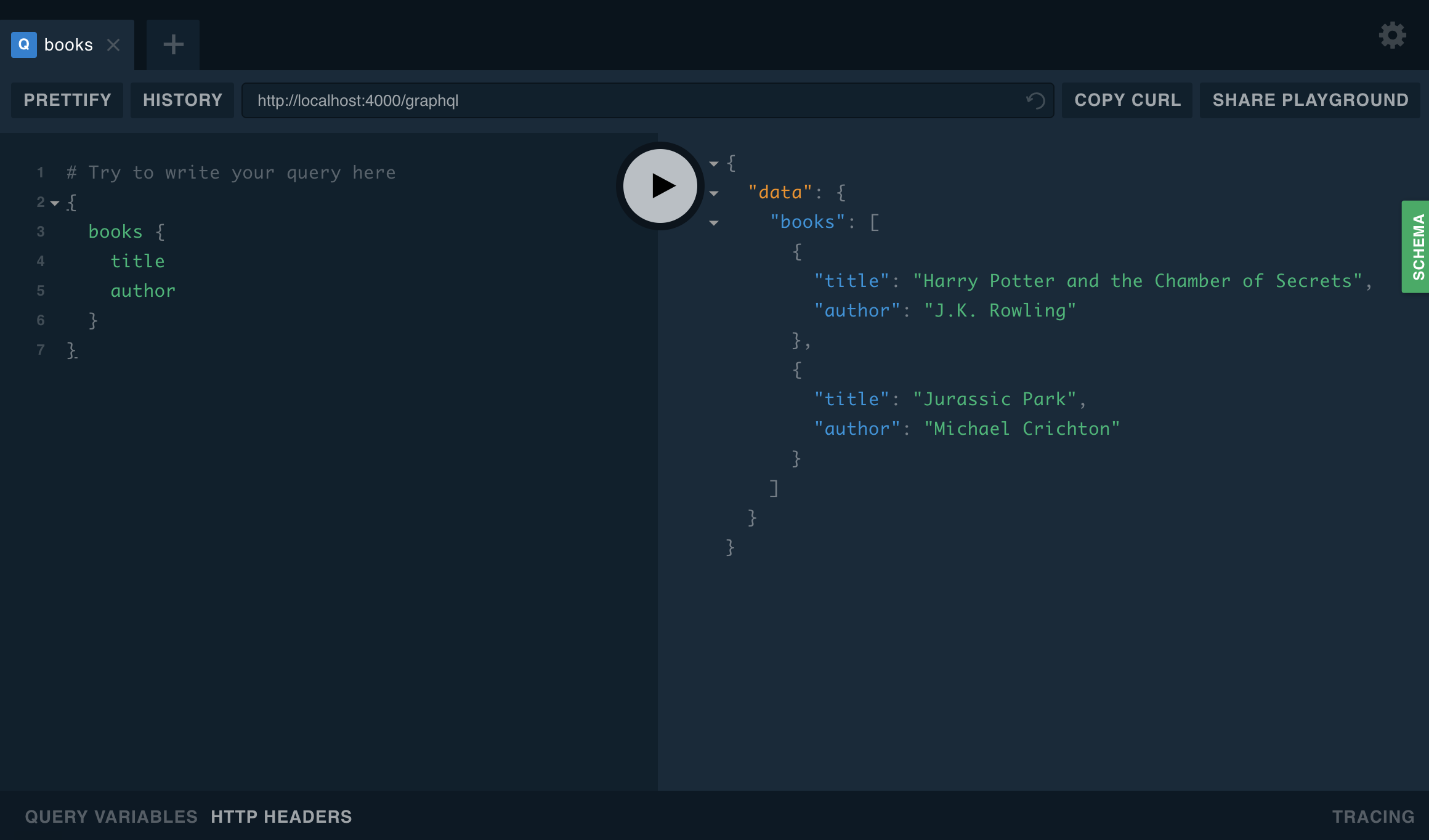
GraphQL 引入了类型系统、参数、查询与变更类型、标量类型、枚举类型、接口、联合类型、输入类型等概念。读者可以在这里学习相关概念的描述。这些概念至关重要。
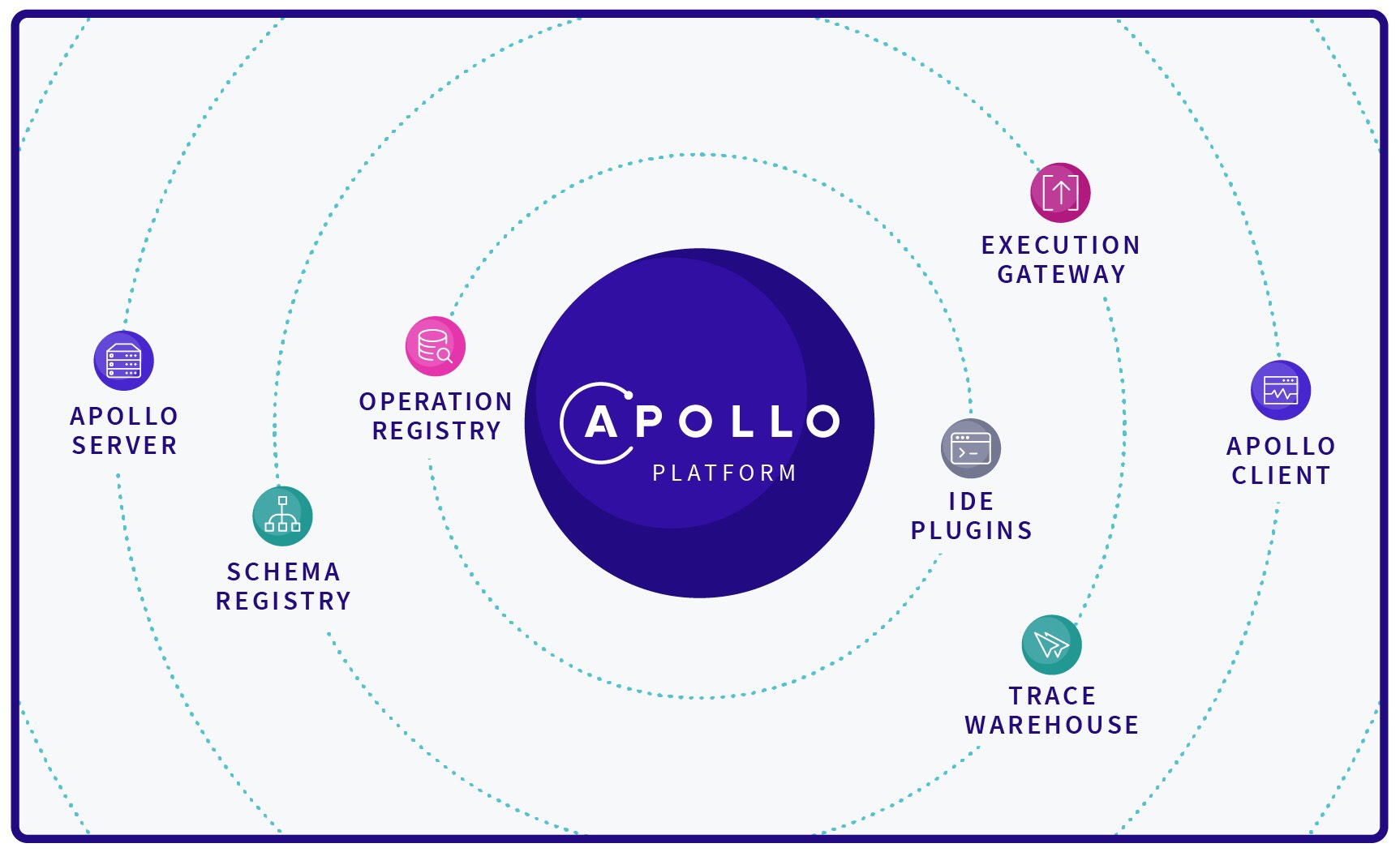
接下来我们打交道的各种程序,无论是前端还是服务端,始终都回避不了一个名字:Apollo。Apollo 是一个通过社区力量帮助你在应用中使用 GraphQL 的一套工具,由 Meteor Development Group开发。本文选型的前端和服务端都最终依赖 Apollo 这个利器。下图是 Apollo 涵盖的领域:
在 Vue 项目中整合 GraphQL
我们以使用 Vue 的项目为例,看一下在前端如何使用 GraphQL。整合 Vue 与 GraphQL 依赖库:vue-apollo。vue-cli 3.x 已经支持工具化引入这个库。
我们以 vue-cli 3.x 为例。
- 建立工程,以
graphql-test为例
vue create graphql-test
- 添加 apollo 插件
cd graphql-test
vue add apollo
此后将安装vue-cli-plugin-apollo,用于配置请求。
为了简单地展示原理,我们暂时不安装样例代码。
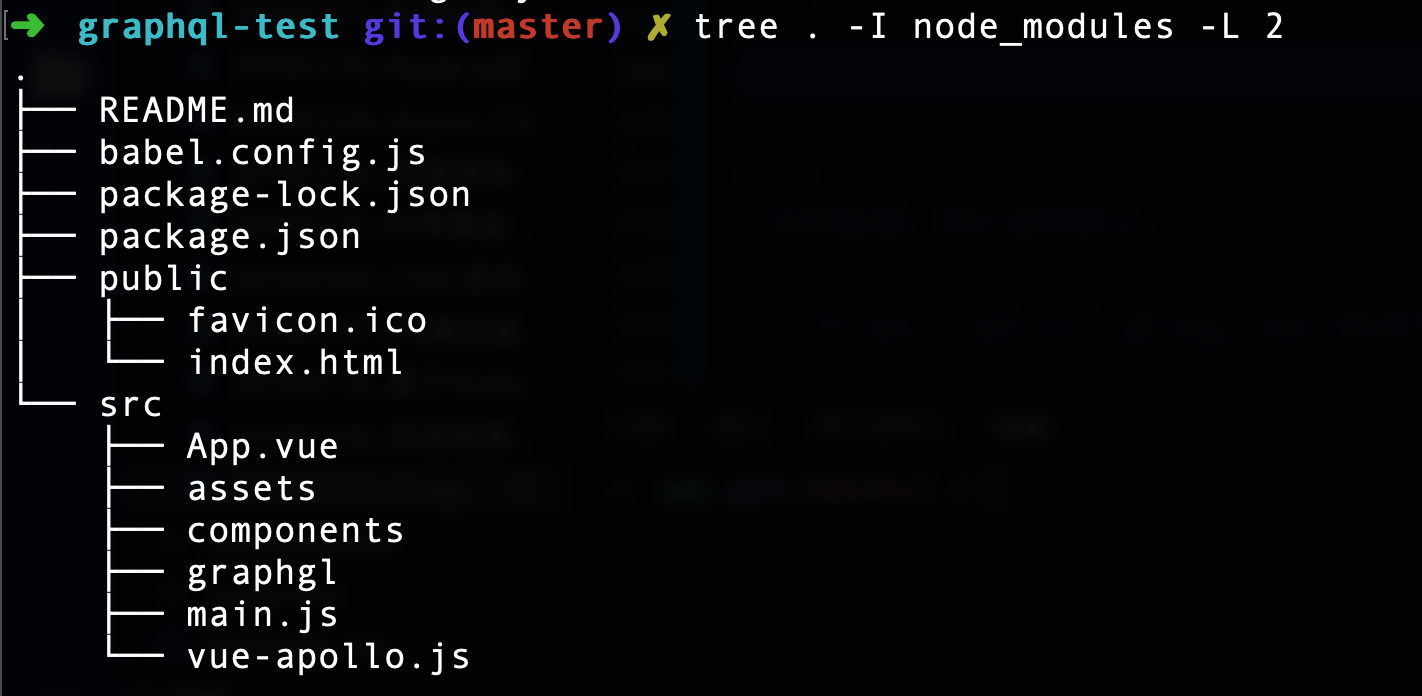
此时,目录结构如下图:
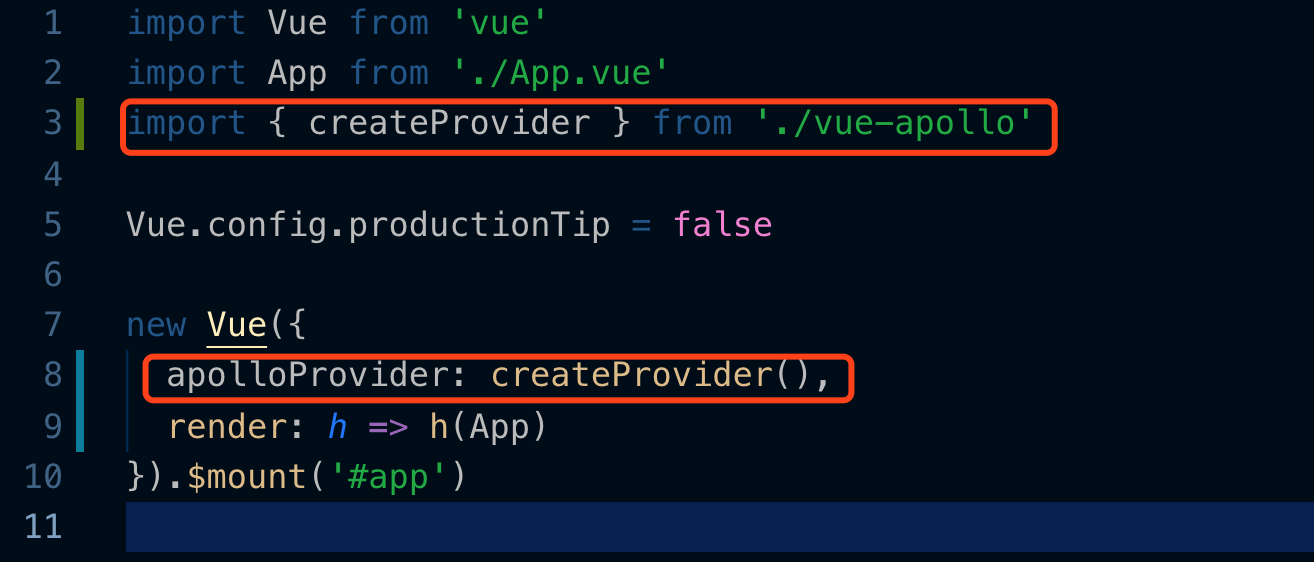
默认地,vue-cli-plugin-apollo已经在入口的main.js为我们引入好了配置文件,并全局地,引入到 vue 组件中:
OK,一起来修改一下HelloWorld.vue,如下:
<template>
<div>
<ApolloQuery :query="require('../graphql/hello.gql')">
<template slot-scope="{ result: { loading, error, data } }">
<div v-if="data">{{ data.hello }}</div>
<div class="book">
<div class="title">Book</div>
<ul v-if="data">
<li v-for="item in data.books">
<span>title: {{item.title}}</span> <span>author: {{item.author}}</span>
</li>
</ul>
</div>
</template>
</ApolloQuery>
</div>
</template>
<style scoped>
.title {
font-size: 14px;
font-weight: bold;
}
.book ul {
margin: 0;
padding: 0;
margin-left: 50%;
transform: translateX(-50%);
}
.book li {
margin: 0;
padding: 0;
list-style: none;
text-align: left;
display: flex;
align-content: space-between;
}
</style>
<script>
export default {
apollo: {},
};
</script>
hello.gql 的内容如下:
query Hello {
hello
books {
title
author
}
}
此时运行:npm run serve。打开浏览器访问:http://localhost:8080。
大家会看到,目前还没有网络返回。为了实现和服务器的交互,我们还需要把服务端建立起来。
在服务器端响应请求
这里需要说明一点,无论是前端还是服务端的响应代码不一定是 Javascript 的。前文提到的各种库列出了主流语言的实现。本文中,以服务端 Javascript 为例来说明。
特别地,如果使用上文提到的 vue-cli 3.0 生成服务端代码也是可以的。这里为了清晰,还是以手动建立为例。
- 建立服务端工程,以
graphql-server-test为例
vue create graphql-server-test
- 安装依赖
cd graphql-server-test
npm init -y
npm install --save apollo-server graphql
- 建立响应文件
server.js
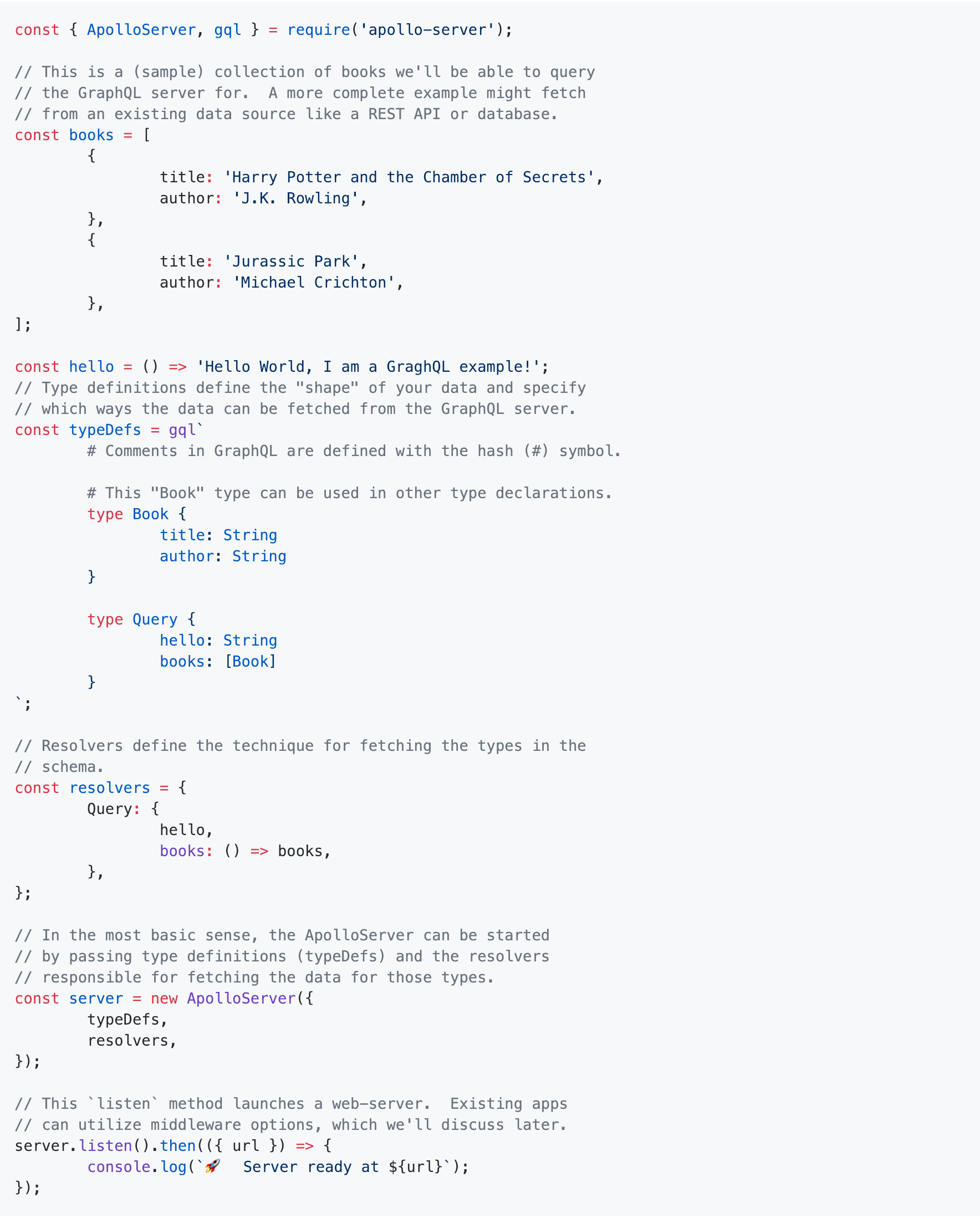
此时,刷新浏览器,可以看到响应。

优势与劣势分析
对于 GraghQL,优势在于可以有效地降低请求数和请求载荷,提升效率。同时可以灵活地应对各种客户端需求以及多变的业务需求。当然也客观地增加了请求实现的复杂度,同时由于请求对象的个性化,不能充分利用 HTTP 的缓存,也是一个值得重视的问题。
这里是Nate Barbettini在 From Iterate Conference 2018 上的演讲以及问答视频,比较客观的比较了 RPC、REST 和 GraghQL 三种方式的优劣,有兴趣的同学可以了解。
Next
本系列下一篇,将以一个完整的前后端示例,带读者亲自体验在实际项目中的 GraphQL。
Comments